


In this ever-changing landscape of the internet, there are more security concerns than ever. Hence, with each passing day, security measures are constantly enhanced to prevent website attacks, such as bot attacks. Enter Cloudflare, a renowned technology that provides rock-solid web security with an enhanced focus on performance. It is one of the most robust and widely used bot protection services on the internet.
Cloudflare Bot Management is a premium tool suite that protects against harmful bots and digitally automated attacks. It also provides advantages against threats from bots, including credential stuffing, web bypassing, and account hacking.
What is Gologin?
Gologin is an anti detect browser that provides ample tools to be an ideal choice for web scraping. It has a fully functional free demo that can be used to test the solution created by the user. Gologin can be quickly integrated with the playwright, an open-source Python library that minimizes the impact on the production. It also supports creating multiple profiles, which results in different fingerprints that can be used for experiments. Cloudflare identifies GoLogin-operated browser profiles as standard Chrome profiles.
What is Cloudflare Bot Management?
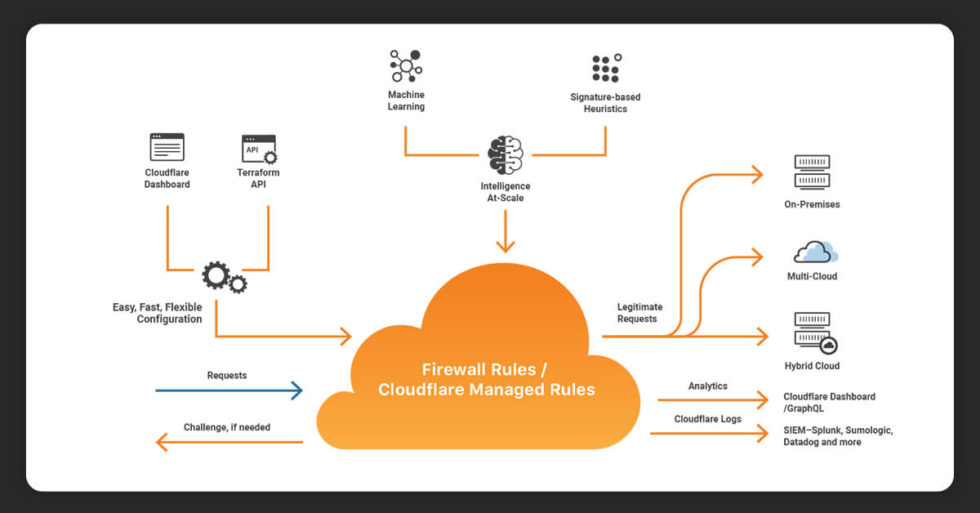
Cloudflare Bot Management is a collection of security tools designed to keep websites safe from malicious bots and automated attacks. It protects against bot threats like credential stuffing, web bypasses, and account takeover.
The Web Application Firewall (WAF) is included in Cloudflare Bot Management. This helps prevent malicious traffic from reaching a website’s origin server. The WAF Cloudflare security measures analyze traffic patterns and identify potential threats using advanced machine learning algorithms.
Another useful feature of Cloudflare Bot Management is the ability to resolve DNS queries for known good bots. Legitimate bots can now access a website without being blocked by security measures.
Why is Bypassing Cloudflare Difficult?
Bypassing Cloudflare is problematic because, unlike conventional security measures that use IP tracking and CAPTCHAs. Cloudflare uses an advanced set of machine learning algorithms, which are then used to analyze incoming requests to a website.
Generally, bots follow a specific pattern most likely to be different from a human user, such as making tremendously large requests in a shorter timeframe or having inconsistent web fingerprints, which can further be classified into suspicious categories.
It is also rigid to bypass Cloudflare bot management solutions because they are consistently updated and taught to identify different web scraping bots. In addition, the solution for each webpage is highly customized to meet the prerequisites, which means that something other than what works for one website may work for another.
How Does Cloudflare Detect the Bots?
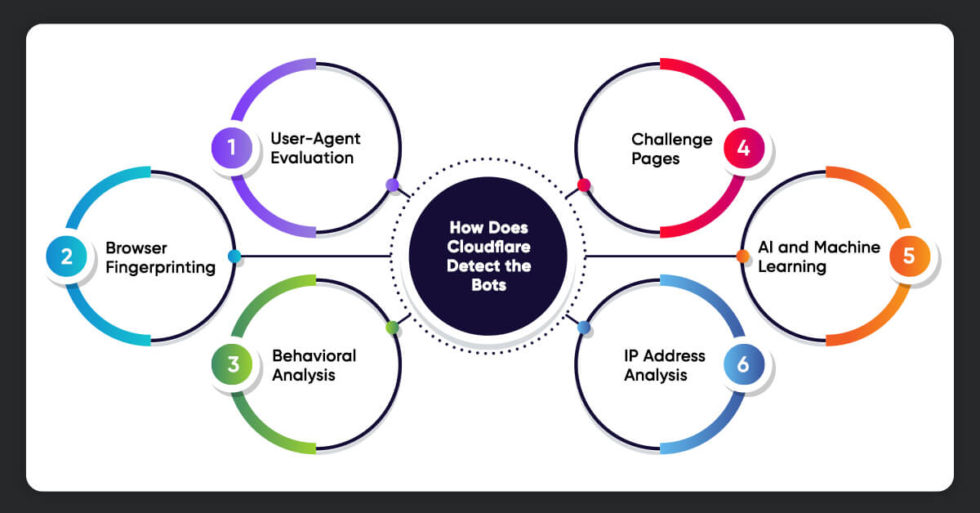
Cloudflare employs various security techniques to detect and mitigate bot traffic on the host websites. However, Cloudflare does not disclose the details of the exact techniques they used. But we are here to provide some standard techniques that Cloudflare and other web security services use to identify and differentiate between human users and automated bots.
1. User-Agent Evaluation
Web browsers communicate a text string known as the user-agent to web servers to identify themselves. Bots frequently employ strange or generic user-agent strings, by examining these strings, Cloudflare can recognize and prevent known bot signatures.
2. Browser Fingerprinting:
Cloudflare can use browser fingerprinting techniques to examine several aspects of the user’s browser, including installed fonts, screen resolution, and other features. Bots frequently have recognizable, consistent fingerprints that can be utilized for identifying them.
3. Behavioral Analysis:
Cloudflare looks at user behavior to distinguish between humans and bots. Analyzing keyboard strokes, mouse movements, and other website interactions falls under this category. Behavioral analysis can identify the fast and artificial interactions that automated bots frequently display.
4. Challenge Pages:
Users whose activity is considered suspect by Cloudflare may be presented with challenge sites, such as JavaScript challenges or CAPTCHAs. These tasks are meant to be simple for humans to complete yet challenging for robots. Reputable users can demonstrate their legitimacy by finishing these tasks successfully.
5. AI and Machine Learning:
Cloudflare leverages artificial intelligence and machine learning techniques to continuously refine and enhance its ability to identify new and constantly dynamic bot patterns. Cloudflare tailors its protection services for each client website using different techniques due to different requirements.
6. IP Address Analysis:
Cloudflare tracks and examines the actions of incoming traffic. Requests from a single IP address frequently or in strange ways could be signs of automated bot activity. Cloudflare can take action like rate limitation or IP address blockage to safeguard the website.
What are Some of the Most Effective Methods to Bypass Cloudflare Bot Protection?
Cloudflare provides DDoS protection against bot attacks. It acts as a proxy between the user and the server and thus hides the original IP address. They need to make accessing information from the web pages protected by Cloudflare easier for web scrapers.
1. Bypassing Cloudflare CDN by Calling the Origin Server
When someone tries to access a website or web application by contacting the server directly instead of using the Cloudflare content delivery network (CDN), they bypass the CDN and go straight to the source server.
Requests made by users to a website secured by Cloudflare usually pass via the company’s extensive worldwide server network. Before forwarding the requests to the origin server that hosts the website, Cloudflare caches the content, then optimizes delivery and incorporates security measures.
This approach promotes the website’s overall performance and security by offloading traffic and lowering latency. It is crucial to remember that using CDN services like Cloudflare without the required authorization is unethical and potentially illegal. CDN provider services are meant for legal purposes and are essential in defending websites against online dangers.
2. Overriding Cloudflare Waiting Room
Usually, users are asked to wait a while before being allowed access to a website. A CAPTCHA or other security gates might also be included to confirm that the user is human and not a bot.
The following factors can impact the time it takes to avoid the waiting room:
- The application of automated tools
- The sort of challenge used by Cloudflare
- The Level of security protections used by the website being accessed.
Reverse Engineering the Cloudflare JavaScript Challenge:
The Cloudflare JavaScript challenge can be difficult to reverse engineer, but it is doable with the appropriate tools and skills. This guide will walk you through the stages needed in reverse engineering the Cloudflare JavaScript challenge, complete with code examples.
Step 1: Examine the network log
The first step is to inspect the requests and responses in the browser’s network log. Look for requests with a 503-error code or a “cf-chl-bypass” cookie. These are the requests that commonly set off the Cloudflare JavaScript challenge.
The code uses the requests library to send an HTTP GET request to the target website URL. The response content, together with the HTML content of the website and any loaded scripts, is printed to the console.
Experienced developers and security experts possess an edge when bypassing the waiting area. They understand the underlying web technologies and the technologies that Cloudflare uses. This enables them to complete the task faster and more effectively than others with less expertise.
Step 2: Debug the Cloudflare JavaScript challenge script
Then, open the browser’s debugger and look for the JavaScript file that is causing the problem. This file is typically titled “cf_chl.js” or “challenge.js”. Set a breakpoint at the beginning of the script to halt execution and facilitate examination.
import requests
from bs4 import BeautifulSoup
url = “https://example.com”
response = requests.get(url)
soup = BeautifulSoup(response.content, “html.parser”)
script_tag = soup.find(“script”, {“src”: “/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1”})
js_code_url = “https://example.com” + script_tag[“src”]
js_code = requests.get(js_code_url).text
# Add print statements to debug the JS code
def challenge_callback(solved_token):
print(“Solved token:”, solved_token)
context = {
“success”: False,
“callback”: challenge_callback
}
exec(js_code, context)
- Using the requests library, this code sends an HTTP GET request to the specified website URL.
- The BeautifulSoup library is used to parse the response content in order to locate the script tag containing the Cloudflare challenge script.
- The source URL of the script tag is extracted, and another HTTP GET request is sent to obtain the script’s contents.
- The exec function is used to run the contents of the received script. A custom context is handed in to allow for the definition of callback functions.
- The custom context receives an example callback function that is defined. It will be triggered if the Cloudflare challenge is successfully completed.
Step 3: Deobfuscate the Cloudflare JavaScript Challenge Script
The Cloudflare JavaScript challenge script is usually obfuscated to prevent reverse engineering. To deobfuscate the script and make it easier to read, use a tool like JSNice or Unminify. Alternatively, you can use the browser debugger’s built-in JavaScript beautifier.
import requests
from bs4 import BeautifulSoup
from jsbeautifier import beautify
url = “https://example.com”
response = requests.get(url)
soup = BeautifulSoup(response.content, “html.parser”)
script_tag = soup.find(“script”, {“src”: “/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1”})
js_code_url = “https://example.com” + script_tag[“src”]
js_code = requests.get(js_code_url).text
# Use jsbeautifier to deobfuscate the JS code
deobfuscated_code = beautify(js_code)
def challenge_callback(solved_token):
print(“Solved token:”, solved_token)
context = {
“success”: False,
“callback”: challenge_callback
}
exec(deobfuscated_code, context)
- This code is identical to Step 2 until the challenge script contents are retrieved.
- The js beautifier library is used to deobfuscate and make the script contents more readable.
- The custom context receives a defined sample callback function. If the Cloudflare challenge is successfully completed, it will be called.
Step 4: Analyze the deobfuscated script
It’s time to analyze the script after it’s been deobfuscated. Search for the functions that either validate the answer or produce the challenge token.
These functions are typically named “gen_challenge” or “verify.” Look for recurring patterns or algorithms in the script. If these are discovered, they can be used to generate the appropriate challenge token or response.
import requests
from bs4 import BeautifulSoup
from jsbeautifier import beautify
url = “https://example.com”
response = requests.get(url)
soup = BeautifulSoup(response.content, “html.parser”)
script_tag = soup.find(“script”, {“src”: “/cdn-cgi/challenge-platform/h/b/orchestrate/jsch/v1”})
js_code_url = “https://example.com” + script_tag[“src”]
js_code = requests.get(js_code_url).text
# Use jsbeautifier to deobfuscate the JS code
deobfuscated_code = beautify(js_code)
# Extract relevant code snippets
challenge_function = “”
challenge_callback = “”
for line in deobfuscated_code.split(“\n”):
if “function ” in line and “challenge_” in line:
challenge_function += line + “\n”
elif “success:!1,” in line:
challenge_callback += line + “\n”
# Create a custom environment for executing the JS code
class ChallengeEnvironment:
def __init__(self, callback):
self.callback = callback
self.success = False
def setTimeout(self, func, delay):
func()
def atob(self, str):
return bytes(str, “ascii”).decode(“base64”)
# Execute the challenge function with the custom environment
context = ChallengeEnvironment(challenge_callback)
try:
exec(challenge_function, context.__dict__)
except Exception as e:
print(“Error:”, e)
if context.success:
print(“Challenge solved successfully!”)
else:
print(“Failed to solve the challenge.”)
This code is identical to Step 3 until the challenge script contents are deobfuscated.
- Relevant code snippets from the deobfuscated script are extracted, including the challenge function and the success callback function.
- To simulate the browser environment and allow the challenge script to run properly, a custom environment class is defined.
- The challenge function is run in the custom environment, and any errors are reported to the console.
- The Cloudflare challenge was successfully solved if the success callback function was called with the success flag set to True.
- Employing Cloudflare Solvers
The specific problem that Cloudflare presents can affect the efficacy of open Cloudflare solvers. Specific solvers are generally unparalleled at handling particular kinds of problems.
For instance, two well-known Python packages that are useful for resolving simple JavaScript issues are cloud scraper and cfscrape. Both replicate how users might interact withCloudflare DDoS challenge results using headless browsers. Often, simple problems are easy to solve.
The user is given the cookies and any other required information to complete the task via FlareSolverr, which launches a headless browser.
How to Scape Data with FlareSolverr
If FlareSolverr is properly configured, you can easily send the URLs you want to scrape to its HTTP server and expect the web content and cookies to be returned. To scrape with FlareSolverr, we need a tool that makes it simple to send HTTP requests.
We’ll stick with the Python Requests library because it’s the de facto standard for making requests.
- Create a Python file, import Requests, define the FlareSolverr API URL, and specify the content type as follows:
| scraper.py
import requests api_url = “http://localhost:8191/v1” headers = {“Content-Type”: “application/json”}
|
- Next, specify the payload that will be included in the request. It should include the HTTP method, the URL to be scraped, and the maximum timeout in this case. Let’s use NowSecure, a Cloudflare-protected test website, as the target URL once more.
| scraper.py
data = { “cmd”: “request.get”, “url”: “https://nowsecure.nl/”, “maxTimeout”: 60000 } |
- Then, send a POST request to the FlareSolverr API with the required parameters.
| scraper.py
response = requests.post(api_url, headers=headers, json=data) |
- Now, it is important to verify how it works:
| scraper.py
print(response.content) |
- When you put it all together, you should have the following Python code.
| scraper.py
import requests api_url = “http://localhost:8191/v1” headers = {“Content-Type”: “application/json”}
data = { “cmd”: “request.get”, “url”: “https://nowsecure.nl/”, “maxTimeout”: 60000 } response = requests.post(api_url, headers=headers, json=data) print(response.content)
|
- Your response should include the following values:
| Output
{ “status”: “ok”, “message”: “Challenge solved!”, “solution”: {“url”: “https://nowsecure.nl/”, “status”: 200, “cookies”: [{ “domain”: “nowsecure.nl”, “expiry”: 1681830200, “httpOnly”: false, “name”: “cf_chl_rc_m”, “path”: “/”, “sameSite”: “Lax”, “secure”: false, “value”: “1”}], “userAgent”: “Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36”, “headers”: {}, “response”: “<html lang=\”en\”><head>\n <!– Required meta tags –>\n <meta charset=\”utf-8\”>\n ……// ….. <h1>OH YEAH, you passed!</h1>\n <p class=\”lead\”>you passed!</p> …..//…”, }
|
Using Privacy Browsers For Web Scraping Protection
What is a Privacy browser?
Privacy browsers (also known as multi accounting or antidetect browsers) are typically built on Chromium but include features that improve user privacy.
Typically, they generate new fingerprints that appear authentic to websites, protecting the user’s true location. This is the primary distinction between a traditional Playwright or Selenium execution.
In easy terms, when you use Playwright under Chrome, the server knows you’re using a legitimate version of Chrome. Because of its device fingerprint, it is running from a Datacenter machine. A privacy browser is a version of Chromium that has been configured for maximum privacy.
How Does it Help in Web Scraping Protection?
Using web browsers emphasizing user privacy and security when participating in web scraping activities is known as using privacy browsers for web scraping protection. Web scraping is the process of obtaining data from websites for various purposes. It is crucial to carry out web scraping morally and follow the website’s terms of service.
Features that lessen users’ digital footprints are frequently included in privacy browsers. This involves restricting or turning off tracking tools like cookies, making it harder for websites to recognize and stop automated scraping bots.
Users can often alter their User-Agent strings using privacy browsers. Browsers give information to websites called User-Agent, which tells them what browser and operating system they use.
Utilize Headless Browsers
Headless web browsers imitate how users behave when using a standard browser. They enable users to use cookies, run JavaScript, and navigate the website usually. This makes detecting and blocking artificial traffic more challenging for Cloudflare. The traffic emerges to be a legitimate user rather than an automated bot.
Value Added Information:
Puppeteer is an open-source library of Node.js that offers a high-quality and tailored API to control the headless Chrome and google browsers.
It is a popular headless browser for getting around Cloudflare. Cloudflare-protected web data can be accessed using Puppeteer.
It can use JavaScript to solve challenges and extract the required cookies required to prevent it from happening again.
Headless browsers can be a powerful tool for avoiding Cloudflare. It is critical to consider the following factors:
The amount of data scraped
The overall level of website security
The technical proficiency of the user
The resources are available for running headless browsers.
API to Bypass Cloudflare
Another efficient method of getting around Cloudflare’s security measures is through smart proxy APIs. Smart proxy APIs are made to reroute HTTP traffic using a pool of residential IP addresses. Websites find it more challenging to identify and prevent automated traffic.
A sizable database of actual residential IP addresses is accessible through these APIs. The API routes requests to these IP addresses to conceal the requests’ true origin. As a result, Cloudflare finds it more challenging to recognize and block automated traffic.
Cloudflare CAPTCHA avoidance
Captcha services can also be used to circumvent Cloudflare’s JavaScript challenges. This is one of the most expensive methods of accomplishing the task (especially for larger volume tasks). However, it is sometimes the only way that works.
How to Bypass CAPTCHA?
Bypassing Cloudflare’s JavaScript obstacles requires capturing the challenge. Then, send it to the API of the captcha-solving service.
The service would then return the solution to the challenge, which you could use to bypass the challenge and gain access to the protected website.
It should be noted that using a captcha-solving service is not always dependable. The service may be unable to solve or take longer to solve certain types of captchas.
Make an effort to analyze and comprehend your target. Some websites will only use the highest security level during specific hours or days of the week. You won’t need to add the extra effort of CAPTCHA solvers if you can identify them and skip them. Furthermore, we recommend implementing some (or all) of the methods described.
How can Gologin be a Game-Changer?
Gologin allows for managing up to 10,000 profiles with different access levels simultaneously. With cloud launch and storage support, one can access and manage profiles from anywhere, anytime, and on any device. It is also one of the few browsers that supports all types of proxies and TOR (free, open-source software enabling anonymous communication). Gologin has features for the mass import and export of profiles and cookies.
Quick Recap to Bypass Cloudflare Bot Protection
We have compiled several techniques and methods to bypass the bot protection. But let’s have final tips to avoid bot protection to perform data scraping activities.
How to Get Over Cloudflare Passive Bot Detection
Disable JavaScript:
This will prevent Cloudflare from gathering this information and allow you to avoid this detection mechanism. However, because some websites rely heavily on JavaScript for functionality, this may not be appropriate for all use cases.
Use a Proxy for JavaScript Rendering:
Cloudflare’s passive bot detection can detect bots that do not execute JavaScript. You can avoid this detection mechanism by using a proxy service that supports JavaScript rendering. A JavaScript rendering proxy service will run it on the server and return the page to the client.
Use a Web Scraping Framework:
Cloudflare’s passive detection can detect bots that do not behave like human users. You can avoid this detection mechanism by using a web scraping framework that can imitate the behavior of a real user.
How to Get Over Cloudflare Active Bot Detection
Change User Agent:
You can avoid this detection mechanism by changing your user-agent string to look like a browser. Install the User-Agent Switcher extension for Chrome or Firefox to quickly switch between user-agent strings.
Rotate IP Addresses:
Cloudflare’s active bot detection can identify bots based on their IP addresses as well. You can avoid this detection mechanism by rotating your IP addresses. If you’re considering a VPN for IP rotation, reading a detailed NordVPN review by Cybernews can help you assess whether it’s the right fit for your needs. Another option is the Tor network, but it may not be appropriate for all use cases.
Use a Headless Browser:
Bots can be identified by Cloudflare’s active bot detection based on their browsing behavior. By using a headless browser, you can mimic real-world browsing behavior and avoid this detection mechanism.
Conclusion
It can be difficult, but it is possible with X-Byte Enterprise Crawling to get around Cloudflare for site scraping and data collection purposes, at least if you know your tools well. Although there are several ways to get around Cloudflare, such as IP address filtering, user-agent switching, and captcha solving, the world of scraping is changing quickly, making older techniques obsolete.
GoLogin might provide a workaround for Cloudflare bot protection. However, employing precautionary and moral principles when using such solutions is essential. Security measures safeguard online ecosystems, and attempting to get around them without the correct authorization could be against the law and terms of service.
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯

Related Blogs

10 Reasons to Choose X-Byte as Your Web Scraping Partner

Scraping Google Maps for USA Restaurant Leads: A Complete Guide for Food Suppliers
