


What is Web Scraping?
If explain in easy words, Web Scraping is the procedure through which we scrape data from a site, as well as save that in the form that is easily readable, easy to understand, as well as work on.
While we mention ‘Easy to work’, we mean that the data extracted could be used for getting many useful insights as well as answer many questions, getting answers of them might not an easy job to do, if we did not get the data stored in an easy and well-organized manner, i.e. usually in the CSV file, a Database or an Excel file.
How Does Web Scraping Work?

To know web scraping, it’s very important to understand that web pages are created with text-related mark-up languages — the most general being HTML.
Any mark-up language describes the structure of website content. As there are general components as well as tags of the mark-up languages, it makes that much easier for all web scrapers to scrape multiple Amazon products pages. When the HTML gets parsed, the web scraper scrapes the required data as well as stores it.
Notice: Not all the websites permit Web Scraping, particularly when personal data of the users get tangled, so we need to always make sure that we don’t search too much, as well as don’t get hands on data that could belong to somebody else. Websites usually have protections as well as they might block the website access if they observe us extracting a huge amount of data from the website.
For the project here, we wanted to search how data of different pages could be scraped vigorously (without understanding how many pages as well as without any hard coding URLs for every page) for Amazon headphone products pages.
Requirement: The Headphone Products page on Amazon has 20 pages showing various headphone brands, new prices, old prices, and total reviews. The objective of this project is to get the product’s name, new pricing, old pricing, and total product reviews for all 20 pages without hard coding URL links to every page every time.
url for this page
Base URL for the Amazon website
Let’s observe the product page structure.

From a page we could see that, we have about 20 pages as well as we require URL for every page for fetching the necessary data from every page.
Let’s search for the HTML structure as well as how the Next button is made.

We can get the href link towards the next page with class “a-last”, while we are on the first page.
What would be the link if we are on 20th Page as well as there are no more pages to direct further?


Therefore, for last page, we would have a class “a-disabled a-last”, therefore we require to check each time if we have the class accessible while fetching every page.
Here is the Python code that will do this action.

In case, the present page structure of HTML do not get class “a-last” then we would add a base URL with next page URL that could be obtained through searching href of the class “a-last” as given above.
Therefore, once we have URL for a new page then we have to download a page using the request module as well as need to convert it in HTML document with BeautifulSoup.
Here is the Python code for doing the above-discussed task.

When we get the URL of the next page as well as HTML document of every page, we require to focus on getting the required data including Product’s name, new prices, old prices, and total reviews.
HTML structure for every variable is given below.
Product Name:

New Pricing:

Old Pricing:

As well as python code for fetching all the information is given below.

As we require to fetch data for every page, we would iterate a page in whereas loop till we reach a class “a-disabled a-last”, while we reach the class, we don’t get further URL then we would end up while loop.
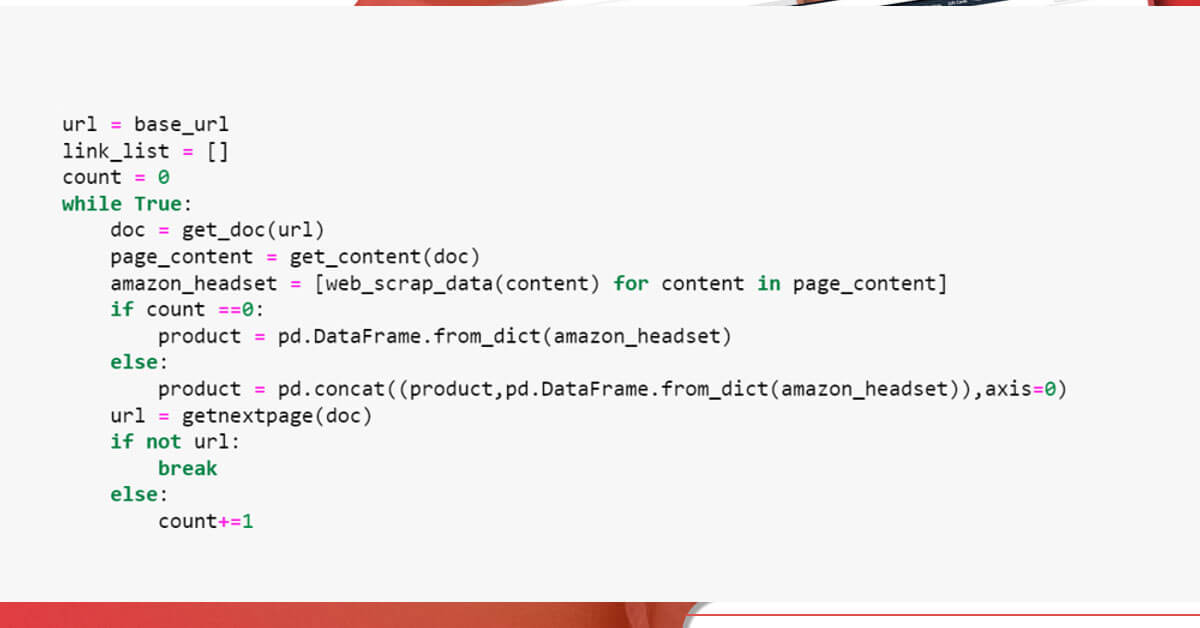
You can get the complete Python code using the GitHub link.
For more information about how to scrape multiple Amazon product pages, contact X-Byte Enterprise Crawling or ask for a free quote!
 ✯ Alpesh Khunt ✯
✯ Alpesh Khunt ✯

Related Blogs

10 Reasons to Choose X-Byte as Your Web Scraping Partner

Scraping Google Maps for USA Restaurant Leads: A Complete Guide for Food Suppliers
